

At a superficial level, adaptive learning may appear to be the matching of content objects to learner needs, in some form of learning sequence with additional elements of feedback and motivation.
However, at the heart of truly effective adaptive learning systems is a “curriculum model”. This is a representation of what the course designer hopes the student will learn; often derived from “learning outcomes”, “learning objectives”, or the “scheme of work” for a course. In the research world, it is called our representation of the “knowledge domain”.
The accuracy of the curriculum model is paramount to the effective personalisation of learning. At Adaptemy, we take pride in the industry-leading quality, accuracy and interpretability of our curriculum models. So how do we build, measure and refine our curriculum models?
What is the curriculum model?
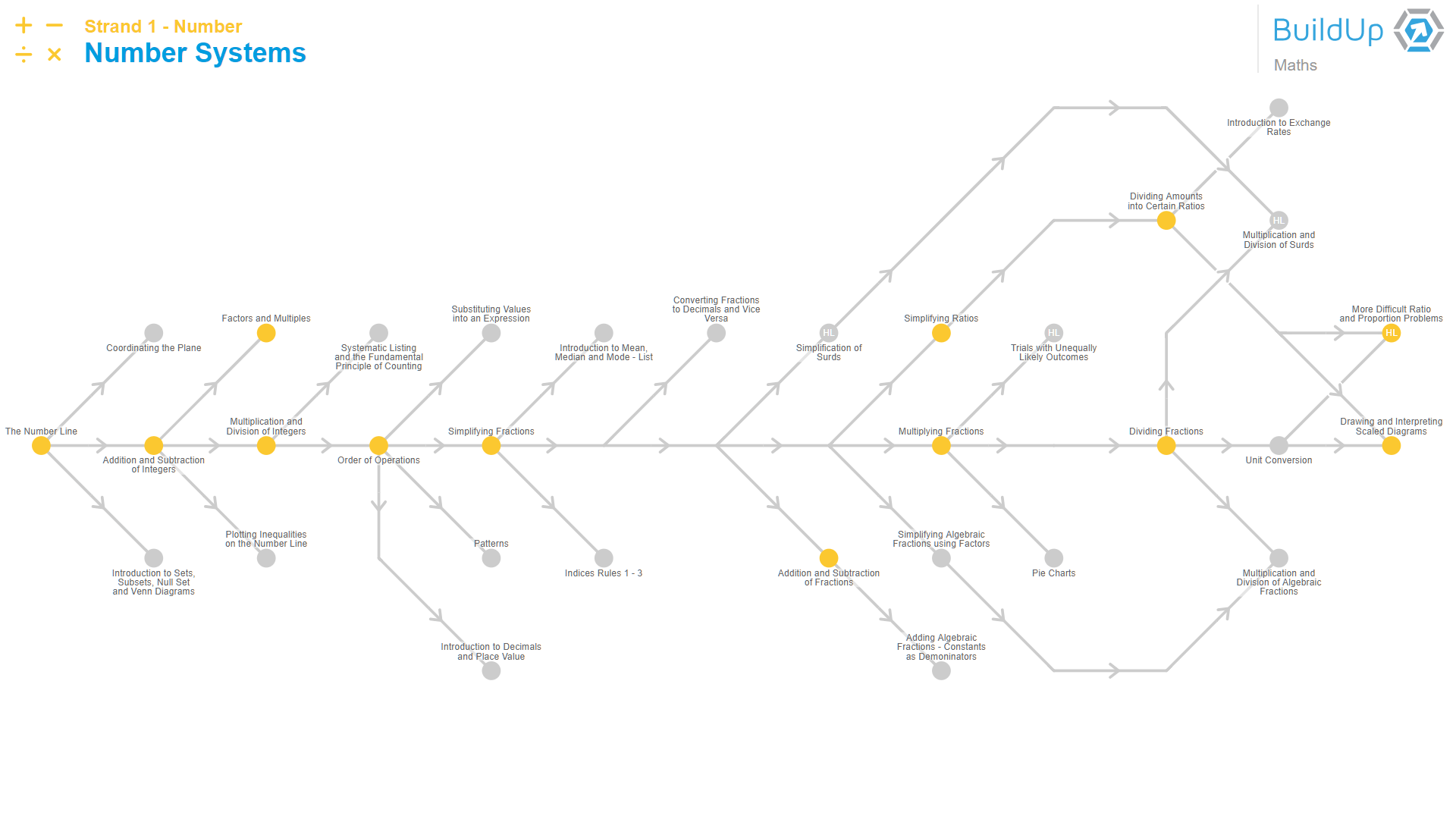
In the Adaptemy engine, the curriculum model is a representation of the “knowledge domain”. It includes knowledge items (concepts) and the relationships between them. The curriculum is represented by two networks: a hierarchy network and a prerequisite network.
The hierarchy network (which includes strands, topics inside a strand, concepts inside a topic) structures the curriculum in a similar way to how it is presented in a book, facilitating easier navigation and higher granularity for assessment.
The prerequisite network (also called the curriculum map) defines the prerequisite relationships between the knowledge items. For example ‘multiplication and division of integers’ is prerequisite for the knowledge item ‘order of operations’.
The model also contains detailed information about these relationships. This rich data indicates the strength of the link and allows for misconception detections, a complex learner model, information propagation and for multiple layers of personalisation and adaptation.
Bayesian Network and Knowledge Space Theory are the underlying foundations of the system and the AI adaptive learning engine uses these theories to update this model.
Updating the Curriculum Model
The engine updates the curriculum model to improve its propagation settings. It uses Bayesian Networks to do this, using learning data to infer the structure of the prerequisite network. It also works to improve an existing prerequisite network based on learning data.
It performs a two-stage update. First, it performs data-driven network learning and then it performs a shape-based network optimisation.
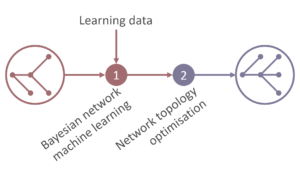
The data-driven network algorithm makes use of Bayesian Network Learning, advanced search, Item Response Theory and complex skill modelling. The algorithm learns representation of both individual and combined skill. And it performs both network structure and parameter learning by using a hybrid constraint-based and score-based algorithm.
The output of the algorithm is an improved prerequisite network structure. The improved prerequisite structure also contains curriculum metrics such as link strength.
The shape-based network optimisation stage performs a set of tests (validations) against the prerequisite network structure and does a topology transformation to improve accuracy and reduce computational complexity. For each optimised model, the algorithm outputs the likelihood-based network score and provides loss-based error metrics based on the learning dataset. This ensures the publisher gets a measure of the improved accuracy of the curriculum model.
On top of this accuracy, the algorithm can account for modelling forgetting and it has the benefit of interpretability.
Our experts can tell you more about the technology inside our engines. Want to know more? Get in touch.



Join the discussion One Comment