

Knowledge tracing refers to the process of modelling a student’s ability as they interact with a learning application.
This is essential in intelligent learning applications because many other modelling, adaptivity and personalisation algorithms within the intelligent learning system use ability estimation to understand behaviour and make recommendations.
Knowledge tracing uses information from previous interactions to build an ability model and then predict future student performance.
Deep learning came to the attention of the AI in education community as it emerged as a successful approach in traditional AI applications, such as computer vision and natural language processing. Committed to improving the accuracy and studying the feasibility of integrated knowledge tracing approaches in real-time intelligent learning applications, the AI in education community began to assess its potential.
The Role of Deep Learning in Knowledge Tracing
The use of deep learning in knowledge tracing, also known as Deep Knowledge Tracing (DKT) is based on the use of recurrent neural networks (RNN) or more specifically, long short term memory (LSTM) – a popular type of RNN.
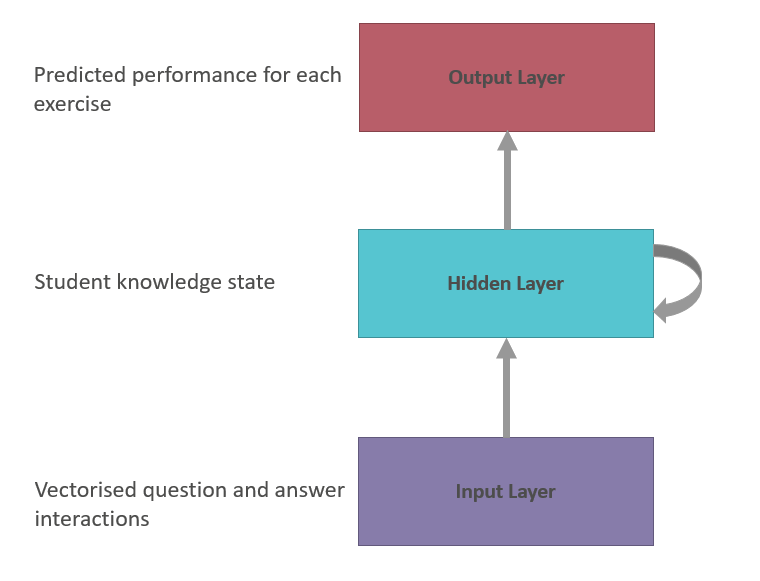 Typically, DKT takes an input sequence and maps it to an output sequence using a set of “hidden” states. Within these hidden states, the encoding of information from past observations is completed and then used for future predictions.
Typically, DKT takes an input sequence and maps it to an output sequence using a set of “hidden” states. Within these hidden states, the encoding of information from past observations is completed and then used for future predictions.
The input sequence is a vectorised question and answer interaction. The hidden states are latent encoding of knowledge states. The hidden state is computed using the LSTM. The output sequence is predicted performance: probabilities of answering each question correctly. The objective is to predict student performance on the next interaction.
How Does DKT Compare to Established Approaches to Knowledge Tracing?
DKT was compared by researchers to previous approaches like Bayesian Knowledge Tracing (BKT), Performance Fact Analysis (PFA) and Item Response Theory (IRT).
Initially, the results were very promising. When compared with extensions of traditional approaches or combined approaches in a layered-based method, DKT showed similar accuracy performance.
But DKT has a vulnerability in how it deals with multiple skill sequences.
A multiple skill sequence is when an exercise is tagged under two or more skills. Instead of encoding the exercise as new combined skill, it is encoded as a sequence of multiple single skills. This is an encoding issue in general but DKT is not robust enough to handle the issue. Special attention is required before using DKT to ensure multiple skill sequencing is processed correctly.
In the Adaptemy engine, this simplified encoding is replaced by the curriculum model.
As noted by researchers, more work should be done to improve the stability and accuracy of the prediction for unseen data, more specifically the unobserved concepts. Having high accuracy on student ability for uncovered concepts is essential in intelligent learning applications and recommendations. Alternatively, intelligent learning applications should integrate and update a curriculum model.
Furthermore, the high computation time and memory load needed by DKT make it difficult to integrate in real-time intelligent learning applications.
DKT falls short in terms of interpretability and explanatory power. DKT is a black box predictive approach, a massive neural network model with tens of thousands of parameters which are near-impossible to interpret.
Our experience at the forefront of AI and adaptive technology in classrooms has shown us that black box solutions do little to incite user confidence.“Explainable AI” is needed in education. The output of algorithms must be explained to users through visualisations before they consume and follow them.
Instead of using DKT for estimating student ability, Adaptemy’s AI engine makes use of a layered architecture. Have a look here at how the ability estimation is done by the Adaptemy AI engine.


